MongoDB
MongoDB
1.下载安装
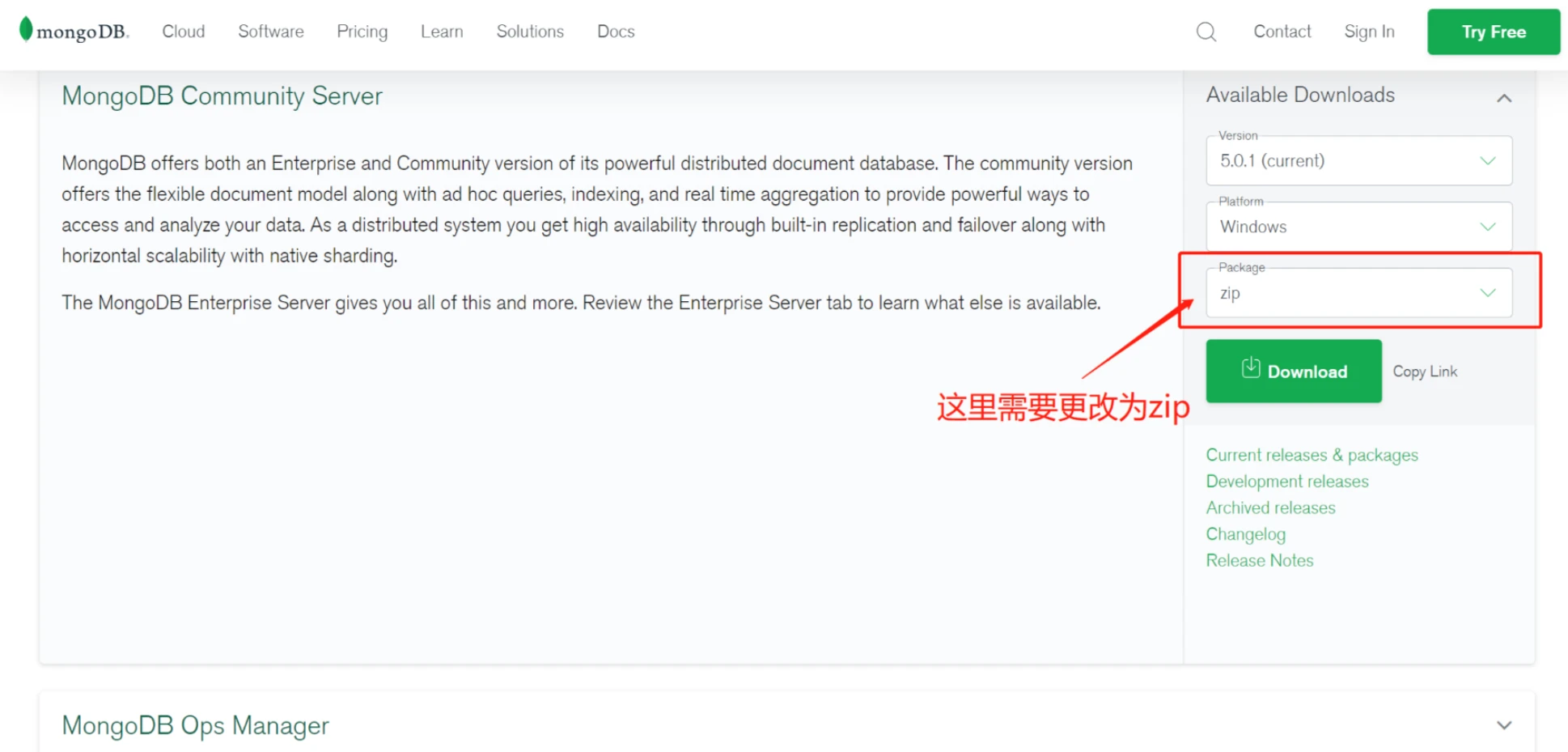
1.1 下载MongoDB
这里我推介下载zip版本,解压到任意盘,由于C盘容易满,所以我放到了D盘。我在D盘创建了一个 mongoDB 的目录,并将压缩包解压到了这个目录里面。
下载地址:https://www.mongodb.com/try/download/community
mongodb 可以不用配置环境变量。配置环境变量只是为了能在终端(cmd窗口)任意路径中执行bin目录中的命令,就是起到一个方便的作用。
环境变量也非常的简单,
H:\mongoDB\bin将这个添加到系统变量path不配置环境变量。如果要启动数据库只能在解压后的 bin 目录中打开 cmd 窗口输入 mongod --dbpath=..\data\db 才可以启动,(这里 dbpath 是指定数据存放的位置,默认在c盘)这里暂时不要启动数据库,因为没有创建 data 目录还有 db 目录
不过等会会将 MongoDB 添加到系统服务中,这样就不用手动来启动了。
1.2 创建目录及配置文件

接下来在 F盘创建 data 目录,继续在 data 目录下创建 db 以及 log。log 目录中还需要创建 mongod.log 文件。这个文件一定要创建否则找不到会报错。
- db:表示数据存储的文件夹
- log:表示日志打印的文件夹

然后在 bin 目录的同级目录创建 mongod.cfg 文件(说明:配置创建路径其实可以随意,但是不建议😅。后缀也可以随意,建议语义化点比如:cfg、config、conf…),并写入如下内容,注意:配置件缩进需要使用tab键(根据自己安装的路径来配置)。
mongod.cfg
# mongod.conf
# for documentation of all options, see:
# http://docs.mongodb.org/manual/reference/configuration-options/
# Where and how to store data.
storage:
dbPath: F:\data\db
journal:
enabled: true
# engine:
# mmapv1:
# wiredTiger:
# where to write logging data.
systemLog:
destination: file
logAppend: true
path: F:\data\log\mongod.log
# network interfaces
net:
port: 27017
bindIp: 127.0.0.1
#processManagement:
#security:
#operationProfiling:
#replication:
#sharding:
## Enterprise-Only Options:
#auditLog:
#snmp:
mongod --config H:\mongodb\bin\mongod.cfg --install --serviceName "mongodb"
- path 是配置打印日志的目录
- dbpath 是配置数据的存储位置
- port 是配置的端口号
1.3 添加到服务(开机自动启动)
只有将 mongodb 添加到系统服务中,他才能自动启动。
注意!!必须以管理员身份打开 cmd 窗口。

这里表示执行配置文件,需要写入你的配置文件路径:
mongod --config H:\mongodb\bin\mongod.cfg --install --serviceName "mongodb"
如果配置文件执行报错,最终无法启动,那么就自己在命令行配置mongoDB,把上面需要执行的命令替换为如下命令即可(注意修改自己的路径)
mongod --dbpath "F:\data\db" --logpath "F:\data\log\mongod.log" --install --serviceName "mongodb"
启动mongoDB:
net start mongodb
后续如果修改 mongoDB 的端口就直接改配置文件,删除服务(服务的删除执行命令:sc delete mongodb),重新执行“添加到服务”
1.4 检查
在键盘上按 “WIN+R”,输入“services.msc”指令确定。
打开服务后,找到MongoDB,如下图表示已经成功!
到这里你已经完成了 mongoDB 的所有配置。接下来如果你需要连接数据库。分两种情况:
- 使用 cmd 命令窗口连接
- 如果你已经配置了环境变量,直接在 cmd 窗口中输入
mongo即可连接成功 - 如果没有配置环境变量,则需要在 bin 目录中打开 cmd 窗口,输入
mongo
- 如果你已经配置了环境变量,直接在 cmd 窗口中输入
2.基本介绍

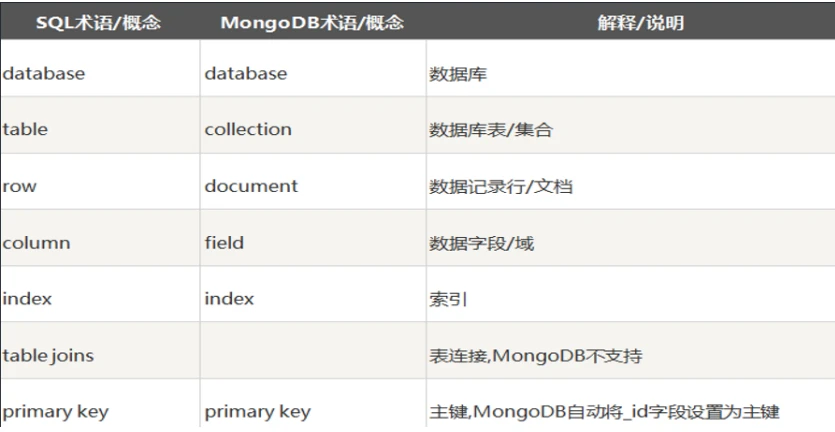
三个概念
- 数据库(database):数据库是一个仓库,在仓库中可以存放集合(collection)
- 集合(collection):一个集合类似于数组,在集合中可以存放文档(document)
- 文档(document):文档数据库中的最小单位,我们存储和操作的内容都是文档


3.基本操作
在MongoDB中,数据库和集合都不需要我们手动创建,当我们创建文档时,如果文档所在的集合或数据库不存在,她会自动创建数据库和集合!
基本指令
- show dbs 或show databases
- 查看所有的数据库
- use xxx
- 切换到指定的数据库
- db
- 查看当前操作的数据库
- show collections
- 查看当前数据库中所有的集合
4.插入文档
- 插入一条数据
- db.collectionName.insertOne( {name:'liu'} )
- db表示的是当前操作的数据库
- collectionName表示操作的集合,若没有,则会自动创建
- 插入的文档如果没有手动提供_id属性,则会自动创建一个
- db.collectionName.insertOne( {name:'liu'} )
- 插入多条数据
- db.collectionName.insertMany( [ {name:'liu5'} , {name:'liu6'} ] )
- 需要用数组包起来
- db.collectionName.insertMany( [ {name:'liu5'} , {name:'liu6'} ] )
- 万能API:db.collectionName.insert()
向集合中插入一个或多个文档 当我们向集合中插入文档时,如果没有给文档指定_id属性,则数据库会自动给文档添加_id 该属性用来作为文档的唯一标识
_id可以自己指定,如果我们指定了,数据库就不会再添加了,如果自己指定_id必须也确保唯一性
db.stus.insert({name:"dselegent",age:28,gender:"男"})
db.stus.insert([
{name:"沙和尚",age:36,gender:"男"},
{name:"白骨精",age:16,gender:"女"},
{name:"蜘蛛精",age:14,gender:"女"}
])
#添加两万条数据
for(var i=0;i<20000;i++){
db.users.insert({username:'liu'+i}) #需要执行20000次数据库的添加操作
}
db.users.find().count()//20000
#优化:
var arr=[];
for(var i=0;i<20000;i++){
arr.push({username:'liu'+i})
}
db.user.insert(arr) #只需执行1次数据库的添加操作,可以节约很多时间
5.查询文档
查询数据
db.collectionName.find() 或db.collectionName.find({})
- 查询集合所有的文档,即所有的数据。
- 查询到的是整个数组对象。在最外层是有一个对象包裹起来的。
- db.collectionName.count()或db.collectionName.length() 统计文档个数
db.collectionName.find({_id:222})
- 条件查询。注意:结果返回的是一个数组
db.collectionName.findOne() 返回的是查询到的对象数组中的第一个对象
- 注意:
#查询集合中的所有文档
db.students.find()
db.students.find({_id:222}).name //错误
db.students.findOne({_id:222}).name //正确
db.stus.find({}).count()
查询所有结果的数量
MongoDB的文档的属性值也可以是一个文档,当一个文档的属性值是文档时,我们称这个文档为内嵌文档
MongoDB支持直接通过内嵌文档的属性进行查询,如果要查询内嵌文档可以则可以通过==.的形式来匹配,且属性名必须使用引号==,双引号单引号都可以
# 1.mongodb支持直接通过内嵌文档的属性值进行查询
# 什么是内嵌文档:hobby就属于内嵌文档
{
name:'liu',
hobby:{
movies:['movie1','movie2'],
cities:['zhuhai','chengdu']
}
}
db.users.find({hobby.movies:'movie1'}) //错误
db.users.find({"hobby.movies":'movie1'})//此时查询的属性名必须加上引号
#2.查询操作符的使用
#比较操作符
$gt 大于
$gte 大于等于
$lt 小于
$lte 小于等于
$ne 不等于
$eq 等于的另一种写法
db.users.find({num:{$gt:200}}) #大于200
db.users.find({num:{$gt:200,$lt:300}}) #大于200小于300
$or 或者
db.users.find(
{
$or:[
{num:{$gt:300}},
{num:{$lt:200}}
]
}
) #大于300或小于200
#3.分页查询
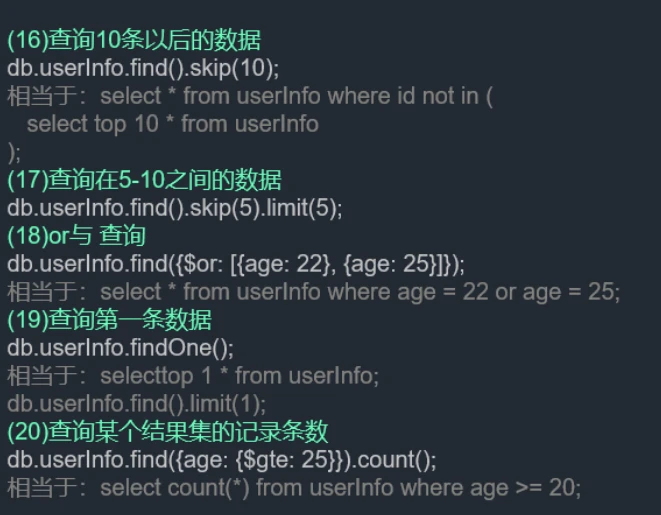
db.users.find().skip(页码-1 * 每页显示的条数).limit(每页显示的条数)
db.users.find().limit(10) #前10条数据
db.users.find().skip(50).limit(10) #跳过前50条数据,即查询的是第61-70条数据,即第6页的数据
#4.排序
db.emp.find().sort({sal:1}) #1表示升序排列,-1表示降序排列
db.emp.find().sort({sal:1,empno:-1}) #先按照sal升序排列,如果遇到相同的sal,则按empno降序排列
#注意:skip,limit,sort可以以任意的顺序调用,最终的结果都是先调sort,再调skip,最后调limit
#5.设置查询结果的投影,即只过滤出自己想要的字段
db.emp.find({},{ename:1,_id:0}) #在匹配到的文档中只显示ename字段
db.stus.find({name:"冉海锋"})
db.stus.find({name:"冉海锋"})[0]
db.stus.find({}).length()
6.删除文档
- db.collection.remove()
- 可以根据条件来删除文档,传递条件的方式和find()一样
- 能删除符合条件的所有文档,默认删除多个
- 如果第二个参数传递一个true,则只会删除一个
- 如果只传递一个{ }作为参数,则会删除集合中的所有文档
- db.collection.deleteOne()
- db.collection.deleteMany()
- db.collection.drop()
删除集合(如果最后一个集合没了,数据库也没了。。)
# 1. db.collectionName.remove()
# remove默认会删除所有匹配的文档。相当于deleteMany()
# remove可以加第二个参数,表示只删除匹配到的第一个文档。此时相当于deleteOne()
db.students.remove({name:'liu',true})
# 2. db.collectionName.deleteOne()
# 3. db.collectionName.deleteMany()
db.students.deleteOne({name:'liu'})
# 4. 删除所有数据:db.students.remove({})----性格较差,内部是在一条一条的删除文档。
# 可直接通过db.students.drop()删除整个集合来提高效率。
# 5.删除集合
db.collection.drop()
# 6.删除数据库
db.dropDatabase()
# 7.注意:删除某一个文档的属性,应该用update。 remove以及delete系列删除的是整个文档
# 8.当删除的条件为内嵌的属性时:
db.users.remove({"hobby.movies":'movie3'})
一般数据库中的数据都不会删除,所以删除的方法很少调用,一般会在数据中添加一个字段,来表示数据是否被删除
7.修改文档
- db.collection.update(查询条件,新对象)
- update()默认情况下会使用新对象来替换旧对象
- update()默认只会修改一个对象
如果需要修改指定的属性,而不是替换,需要使用 “修改操作符” 来完成修改
- $set:可以用来修改文档中的指定属性
- $unset:可以用来删除文档的指定属性
db.collection.updateMany():同时修改多个符合条件的文档
db.collection.updateOne():修改一个符合条件的文档
db.collection.replaceOne():替换一个符合条件的文档
# 1.替换整个文档(只修改查找到的第一个)
db.collectionName.update(condiction,newDocument)
db.students.update({_id:'222'},{name:'kang'})
# 2.修改对应的属性,需要用到修改操作符,比如$set,$unset,$push,$addToSet
/*修改一个文档*/
db.students.update(
{name:"小A"},
{$set:{age:20}}
)
/*修改多个文档*/
db.students.update(
{age:19},
{$set:{age:21}},
{multi:true}/*update中加multi:true可以修改多个文档*/
)
db.collectionName.update(
# 查询条件
{_id:222},
{
#修改对应的属性
$set:{
name:'kang2',
age:21
}
#删除对应的属性
$unset:{
gender:1 //这里的1可以随便改为其他的值,无影响
}
}
)
# 3.update默认与updateOne()等效,即对于匹配到的文档只更改其中的第一个
# updateMany()可以用来更改匹配到的所有文档
db.students.updateMany(
{name:'liu'},
{
$set:{
age:21,
gender:222
}
}
)
# 4.向数组中添加数据
db.users.update({username:'liu'},{$push:{"hobby.movies":'movie4'}})
# 如果数据已经存在,则不会添加
db.users.update({username:'liu'},{$addToSet:{"hobby.movies":'movie4'}})
# 5.自增自减操作符$inc
{$inc:{num:100}} #让num自增100
{$inc:{num:-100}} #让num自减100
db.emp.updateMany({sal:{$lt:1000}},{$inc:{sal:400}}) #给工资低于1000的员工增加400的工资
8.文档之间的关系
一对一
在MongoDB中,可以通过内嵌文档的形式来体现出一对一的关系
db.WifeAndHusband.insert([
{
wife:"黄蓉",
husband:{
name:"郭靖"
}
},
{
wife:"潘金莲",
husband:{
name:"武大郎"
}
}
])
一对多
#用户与订单:
db.users.insert([
{_id:100,username:'liu1'},
{_id:ObjectId("5f87b1deda684b252c2fc7a5"),
username:'liu2'}
])
db.orders.insert([
{list:['apple','banana'],user_id:100},
{list:['apple','banana2'],user_id:100},
{list:['apple'],user_id:101}
])
查询liu1的所有订单:
首先获取liu1的id:
let user_id=db.users.findOne({name:'liu1'})._id;
根据id从订单集合中查询对应的订单: db.orders.find({user_id:user_id})
多对多
#老师与学生
db.teachers.insert([
{
_id:100,
name:'liu1'
},
{
_id:101,
name:'liu2'
},
{
_id:102,
name:'liu3'
}
])
db.students.insert([
{
_id:1000,
name:'xiao',
tech_ids:[100,101]
},
{
_id:1001,
name:'xiao2',
tech_ids:[102]
}
])
9.命令汇总